DeepSeek 全面指南,95% 的人都不知道的9個技巧
當(dāng)前位置:點晴教程→知識管理交流
→『 技術(shù)文檔交流 』
最近,DeepSeek這款A(yù)I工具爆火國內(nèi)外。 雖然許多人都開始嘗試使用它,但有人吐槽說,沒想象中那么牛。 其實問題不在工具,很多人的使用姿勢就搞錯了,用大炮打蚊子,白白浪費(fèi)DeepSeek的強(qiáng)大功能。 接下來,我將為大家分享9個實用技巧,你會發(fā)現(xiàn)DeepSeek遠(yuǎn)比想象中更強(qiáng)大。 DeepSeek的三種模式DeepSeek有三大適用模式:基礎(chǔ)模型(V3)、深度思考(R1)、聯(lián)網(wǎng)搜索。 1. 基礎(chǔ)模型(V3)
基礎(chǔ)模型(V3)是DeepSeek的標(biāo)配,沒有勾選默認(rèn)就是基礎(chǔ)模型。V3版自去年12月升級后,性能大幅提升,堪比業(yè)內(nèi)頂尖模型如GPT-4、Claude-3.5等。 它的作用相當(dāng)簡單,回答日常的百科類問題,幫助用戶快速獲取信息。 不管是查詢常見知識、處理簡單的文本生成任務(wù),V3都能迅速給出答案。它的優(yōu)點就是高效、便捷,幾乎沒有什么門檻,適用于大部分場景。 尤其是在用戶并不要求復(fù)雜推理、深度分析的情況下,V3就顯得尤為合適。比如你只想問一個簡單的問題,或者需要一個快速的解答,V3足夠應(yīng)付。簡單、直接,是它的最大特點。 2. 深度思考(R1) R1作為DeepSeek的深度推理模型,專門用來解決那些需要復(fù)雜推理和深度思考的問題。它處理的任務(wù)更具挑戰(zhàn)性,比如數(shù)理邏輯推理、編程代碼分析等。 R1模型有660B的參數(shù),并采用了后訓(xùn)練+RL強(qiáng)化學(xué)習(xí)方法,擅長從多個角度分析問題,并給出經(jīng)過嚴(yán)密推理后的解答。 R1決定是一位專家,能夠為你提供精確、深刻的推理和分析。因此,如果你的問題涉及到復(fù)雜的推理,R1便是不二的選擇。 3. 聯(lián)網(wǎng)搜索 聯(lián)網(wǎng)搜索模式是DeepSeek的AI搜索功能,基于RAG(檢索增強(qiáng)生成),這一模式讓DeepSeek不僅能依賴它自己的知識庫,還能根據(jù)互聯(lián)網(wǎng)實時搜索相關(guān)內(nèi)容來回答問題。 換句話說,聯(lián)網(wǎng)搜索不僅讓模型能夠回答2024年7月以后的問題,還可以利用網(wǎng)絡(luò)上的最新信息來補(bǔ)充自己的回答。 如何對標(biāo)其他模型?DeepSeek的三個核心模式,能夠與chatGPT對標(biāo),為我們提供更清晰的選擇。 1. V3對標(biāo)GPT-4o DeepSeek的V3模型堪比GPT-4o,二者的設(shè)計理念和應(yīng)用場景非常相似。V3采用了Moe架構(gòu),擁有671B的參數(shù)量,能夠在百科知識領(lǐng)域提供快速響應(yīng)。 2. R1對標(biāo)o1 R1是DeepSeek的深度推理模型,和OpenAI的o1模型非常類似。二者都在處理推理、深度思考以及復(fù)雜邏輯問題時,展現(xiàn)出了非凡的能力。 R1采用了660B的參數(shù),并且在強(qiáng)化學(xué)習(xí)和后訓(xùn)練方面表現(xiàn)出色。R1更擅長邏輯推理和復(fù)雜問題的解答,在這一點上,R1已經(jīng)超越了o1模型。 知識庫的更新時間目前,DeepSeek的預(yù)訓(xùn)練數(shù)據(jù)已經(jīng)更新到2024年7月。 但對于之后的新聞或技術(shù)動態(tài),DeepSeek的聯(lián)網(wǎng)搜索模式就顯得尤為重要,它能夠根據(jù)網(wǎng)絡(luò)實時獲取最新信息,彌補(bǔ)知識庫的空白。 告別提示詞很多AI熟手可能會囤一堆提示詞模板,但是,DeepSeek 完全不用準(zhǔn)備提示詞,只要簡單明了地描述你的需求,DeepSeek 就能理解并給出精準(zhǔn)的答案。 舉個例子,如果你想讓 DeepSeek 幫你寫一段蛇年拜年祝福語,直接告訴它這個需求,它就能立刻生成多個風(fēng)格的版本。
與DeepSeek的對話,盡量使用簡單、直白的語言。越是接地氣的表達(dá),DeepSeek就越能發(fā)揮其最大潛力。 避免過于正式、結(jié)構(gòu)化的表述,簡單、直白、帶點口語化的語言往往能夠獲得最自然、流暢的答案。 DeepSeek的理解能力非常強(qiáng),不需要過多的引導(dǎo),給它一個清晰的問題,它就能提供精準(zhǔn)的答復(fù)。 “小學(xué)生”溝通技巧與DeepSeek對話時,有時我們可能覺得AI的回答過于抽象。 這其實源于傳統(tǒng)AI模型過于注重結(jié)構(gòu)化表達(dá),結(jié)果都是“八股文”的回答,我們可以借助DeepSeek的“小學(xué)生”溝通技巧。 可以給它一個提示:“我是一名小學(xué)生,請用小學(xué)生能聽懂的話解釋什么是大模型。”
通過持續(xù)追問,獲取詳細(xì)答案運(yùn)用持續(xù)追問的技巧,能夠幫你快速搞清楚一個復(fù)雜問題,大致步驟如下:
例如,我先問DeepSeek:“如何寫好提示詞?”
對于如何提供上下文,我還是不明白,我可以繼續(xù)追問DeepSeek。
最后我讓DeepSeek把對話整理成詳細(xì)的清單格式。
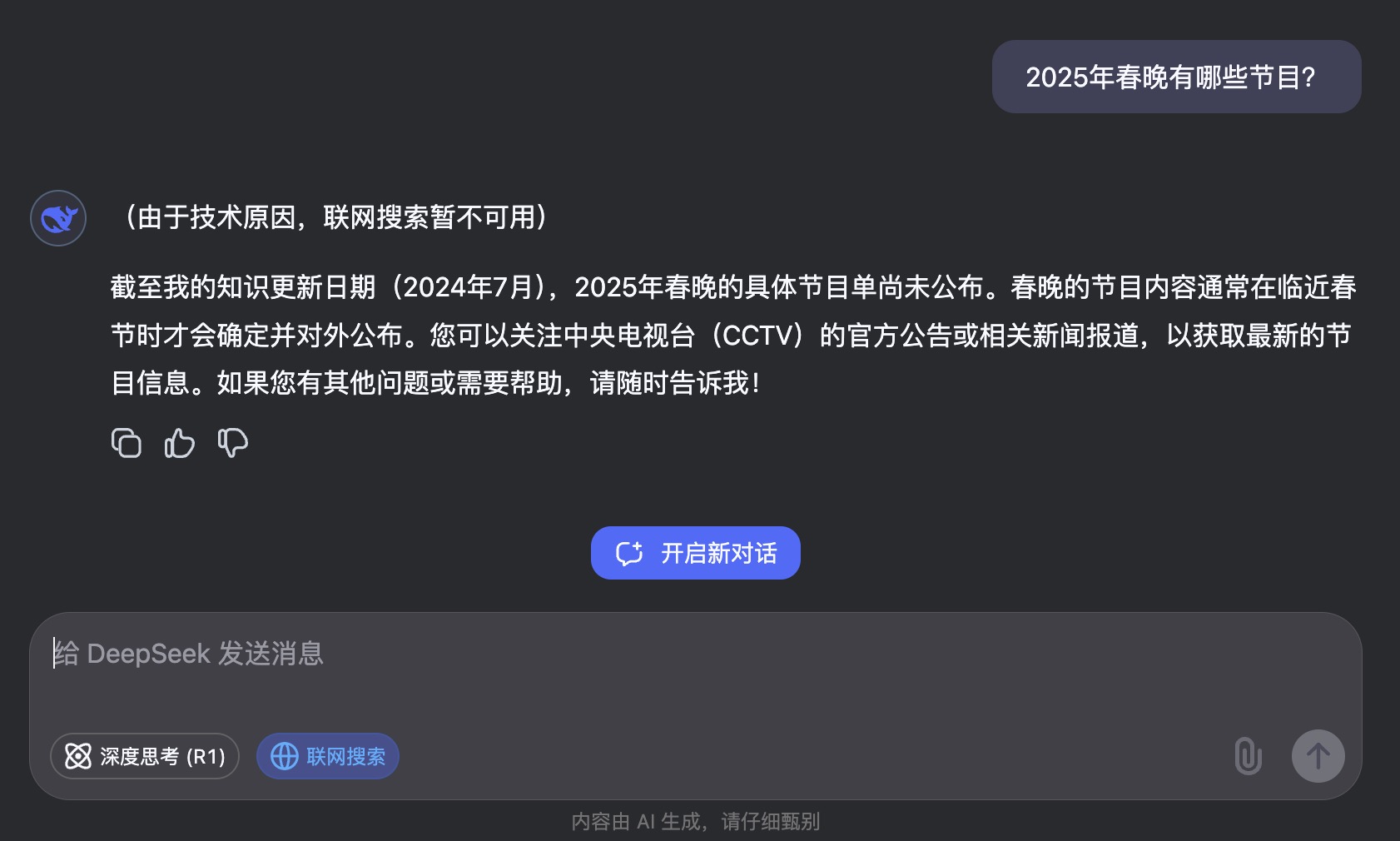
活用聯(lián)網(wǎng)搜索聯(lián)網(wǎng)搜索是DeepSeek的一大亮點,它讓模型在回答時不僅僅依賴預(yù)訓(xùn)練數(shù)據(jù),還能實時從網(wǎng)絡(luò)上檢索最新的信息。 你可以問到2024年7月以后發(fā)生的事件,或者某些新興技術(shù)領(lǐng)域的問題,DeepSeek都能通過聯(lián)網(wǎng)搜索為你提供更準(zhǔn)確、及時的回答。 例如,你問DeepSeek:“2025年春晚有哪些節(jié)目?”它可以在網(wǎng)絡(luò)上找到最相關(guān)的資料,并結(jié)合大語言模型的能力生成確的回答。 但是,最近DeepSeek受國外網(wǎng)絡(luò)攻擊,聯(lián)網(wǎng)搜索暫不可用了,尷尬~
上傳附件功能除了聯(lián)網(wǎng)搜索,DeepSeek還支持上傳附件功能,這為用戶提供了更多個性化的體驗。 通過上傳附件,你可以將自己的私密資料、知識庫、甚至是一些需要深度推理的材料直接交給DeepSeek,讓它基于這些專有的文件進(jìn)行分析和推理。
上傳附件最多支持50個文件,每個文件最大100MB,數(shù)據(jù)量較大的文件,DeepSeek也能處理自如。 R1的三個開放特性對于深度思考(R1)模型,DeepSeek做到了三個重要的開放特性,讓R1不僅僅是一個“黑盒”模型,它的思維過程、訓(xùn)練技術(shù)和模型參數(shù)都是透明開放的。 1. 思維鏈全開放 R1的思維鏈?zhǔn)峭耆_放的,用戶可以看到模型進(jìn)行推理時的每一步邏輯。 這不僅是一個回答,而是一個完整的思考過程。通過這種方式,用戶能獲得最終答案,還能夠理解AI是如何得出這個結(jié)論的。
2. 訓(xùn)練技術(shù)全部公開 DeepSeek采用了RL(強(qiáng)化學(xué)習(xí))技術(shù),通過極少的標(biāo)注數(shù)據(jù)提高了推理能力。 所有的訓(xùn)練技術(shù),包括模型的后訓(xùn)練過程和數(shù)據(jù)增強(qiáng)方法,都是公開的。 這讓廣大網(wǎng)友都能深入理解模型的訓(xùn)練過程,并且可以根據(jù)需要進(jìn)行調(diào)整和優(yōu)化。 3. 開源模型 DeepSeek還將R1的部分模型進(jìn)行開源。雖然R1模型本身的參數(shù)高達(dá)660B,通常只有大公司才能使用,但DeepSeek也為社區(qū)提供了更小的開源模型,讓更多的開發(fā)者和研究者可以使用。 最小的模型只有1.5B參數(shù),適合個人開發(fā)者進(jìn)行實驗和開發(fā)。 這格局太頂了,幫助全球的開發(fā)者共同推動AI的發(fā)展。 以上9個技巧,希望能幫助你更好地使用DeepSeek。歡迎大家在評論區(qū)分享你的使用技巧,一起探討、學(xué)習(xí)。 ?轉(zhuǎn)自https://www.cnblogs.com/tangshiye/p/18696818 該文章在 2025/2/5 9:41:36 編輯過 |
關(guān)鍵字查詢
相關(guān)文章
正在查詢... 的專業(yè)生產(chǎn)管理軟件系統(tǒng),系統(tǒng)成熟度和易用性得到了國內(nèi)大量中小企業(yè)的青睞。")
主要針對港口碼頭集裝箱與散貨日常運(yùn)作、調(diào)度、堆場、車隊、財務(wù)費(fèi)用、相關(guān)報表等業(yè)務(wù)管理,結(jié)合碼頭的業(yè)務(wù)特點,圍繞調(diào)度、堆場作業(yè)而開發(fā)的。集技術(shù)的先進(jìn)性、管理的有效性于一體,是物流碼頭及其他港口類企業(yè)的高效ERP管理信息系統(tǒng)。")
提供了貨物產(chǎn)品管理,銷售管理,采購管理,倉儲管理,倉庫管理,保質(zhì)期管理,貨位管理,庫位管理,生產(chǎn)管理,WMS管理系統(tǒng),標(biāo)簽打印,條形碼,二維碼管理,批號管理軟件。")
OA是一款軟件和通用服務(wù)都免費(fèi),不限功能、不限時間、不限用戶的免費(fèi)OA協(xié)同辦公管理系統(tǒng)。")
|


 400 186 1886
400 186 1886
")