limit深度分頁的坑
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
故事梅雨季,悶熱的夜,令人窒息,窗外一道道閃電劃破漆黑的夜幕,小貓塞著耳機聽著恐怖小說,輾轉反側,終于睡意來了,然而挨千刀的手機早不振晚不振,偏偏這個時候振動了一下,一個激靈,沒有按捺住對內容的好奇,點開了短信,臥槽?告警信息,原來是負責的服務出現慢查詢了。小貓想起來,今天在下班之前上線了一個版本,由于新增了一個業務字段,所以小貓寫了相關的刷數據的接口,在下班之前調用開始刷歷史數據。 考慮到表的數據量比較大,一次性把數據全部讀取出來然后在內存里面去刷新數據肯定是不現實的,所以小貓采用了分頁查詢的方式依次根據條件查詢出結果,然后進行表數據的重置。沒想到的是,數據量太大,分頁的深度越來越深,漸漸地,慢查詢也就暴露出來了。
強迫癥小貓瞬間睡意全無,翻起來打開電腦開始解決問題。 那么為什么用使用limit之后會出現慢查詢呢?接下來老貓和大家一起來剖析一下吧。
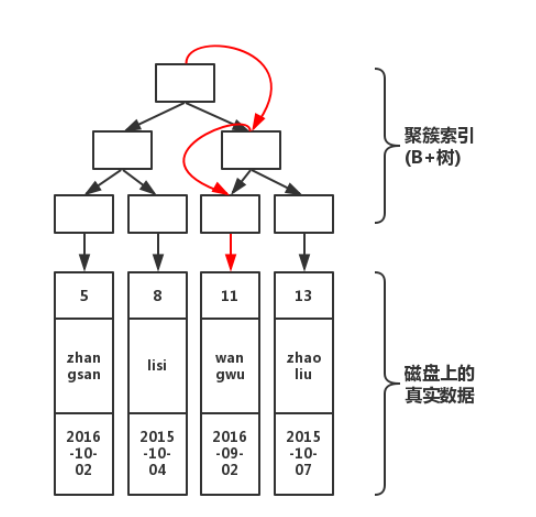
limit分頁為什么會變慢?在解釋為什么慢之前,咱們來重現一下小貓的慢查詢場景。咱們從實際的例子推進。 做個小實驗假設我們有一張這樣的業務表,商品Product表。具體的建表語句如下: 從上述建表語句中我們發現timeCreated走普通索引。 當為淺分頁的時候,如下: select * from Product where timeCreated > "2020-09-12 13:34:20" limit 0,10 此時執行的時間為: 當調整分頁查詢為深度分頁之后,如下: select * from Product where timeCreated > "2020-09-12 13:34:20" limit 10000000,10 此時深度分頁的查詢時間為: 此時看到這里,小貓的場景已經重現了,此時深度分頁的查詢已經非常耗時。 剖析一下原因簡單回顧一下普通索引和聚簇索引我們來回顧一下普通索引和聚簇索引(也有人叫做聚集索引)的關系。 大家可能都知道Mysql底層用的數據結構是B+tree(如果有不知道的伙伴可以自己了解一下為什么mysql底層是B+tree),B+tree索引其實可以分為兩大類,一類是聚簇索引,另外一類是非聚集索引(即普通索引)。 (1)聚簇索引:InnoDB存儲表是索引組織表,聚簇索引就是一種索引組織形式,聚簇索引葉子節點存放表中所有行數據記錄的信息,所以經常會說索引即數據,數據即索引。當然這個是針對聚簇索引。
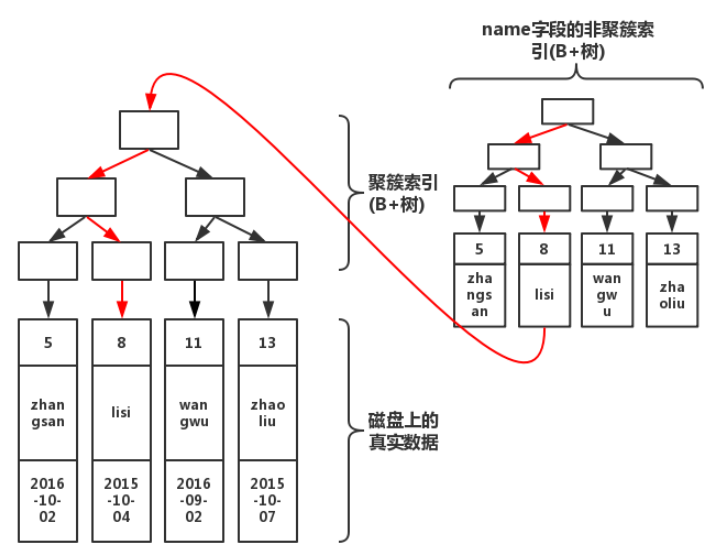
由圖可知在執行查詢的時候,從根節點開始共經歷了3次查詢即可找到真實數據。倘若沒有聚簇索引的話,就需要在磁盤上進行逐個掃描,直至找到數據為止。顯然,索引會加快查詢速度,但是在寫入數據的時候,由于需要維護這顆B+樹,因此在寫入過程中性能也會下降。 (2)普通索引:普通索引在葉子節點并不包含所有行的數據記錄,只是會在葉子節點存本身的鍵值和主鍵的值,在檢索數據的時候,通過普通索引子節點上的主鍵來獲取想要找到的行數據記錄。
由圖可知流程,首先從非聚簇索引開始尋找聚簇索引,找到非聚簇索引上的聚簇索引后,就會到聚簇索引的B+樹上進行查詢,通過聚簇索引B+樹找到完整的數據。該過程比較專業的叫法也被稱為“回表”。 看一下實際深度分頁執行過程有了以上的知識基礎我們再來回過頭看一下上述深度分頁SQL的執行過程。 1、通過普通索引idx_timeCreated,過濾timeCreated,找到滿足條件的記錄ID; 2、通過ID,回到主鍵索引樹,找到滿足記錄的行,然后取出展示的列(回表); 3、掃描滿足條件的10000010行,然后扔掉前10000000行,返回。 結合看一下執行計劃:
原因其實很清晰了: 再深入一點從底層存儲來看,數據庫表中行數據、索引都是以文件的形式存儲到磁盤(硬盤)上的,而硬盤的速度相對來說要慢很多,存儲引擎運行sql語句時,需要訪問硬盤查詢文件,然后返回數據給服務層。當返回的數據越多時,訪問磁盤的次數就越多,就會越耗時。 替換limit分頁的一些方案。上述我們其實已經搞清楚深度分頁慢的原因了,總結為“無用回表次數過多”。 那怎么優化呢?相信大家應該都已經知道了,其核心當然是減少無用回表次數了。 有哪些方式可以幫助我們減少無用回表次數呢? 子查詢法思路:如果把查詢條件,轉移回到主鍵索引樹,那就不就可以減少回表次數了。 select * FROM Product where id >= (select p.id from Product p where p.timeCreated > "2020-09-12 13:34:20" limit 10000000, 1) LIMIT 10; 測試一下執行時間: 我們可以明顯地看到相比之前的27499,時間整整縮短了十倍,在結合執行計劃觀察一下。
我們綜合上述的執行計劃可以看出,子查詢 table p查詢是用到了idx_timeCreated索引。首先在索引上拿到了聚集索引的主鍵ID,省去了回表操作,然后第二查詢直接根據第一個查詢的 ID往后再去查10個就可以了! 顯然這種優化方式是有效的。 使用inner join方式進行優化這種優化的方式其實和子查詢優化方法如出一轍,其本質優化思路和子查詢法一樣。 select * from Product p1 inner join (select p.id from Product p where p.timeCreated > "2020-09-12 13:34:20" limit 10000000,10) as p2 on p1.id = p2.id 測試一下執行的時間:
咱們發現和子查詢的耗時其實差不多,該思路是先通過idx_timeCreated二級索引樹查詢到滿足條件的主鍵ID,再與原表通過主鍵ID內連接,這樣后面直接走了主鍵索引了,同時也減少了回表。 上面兩種方式其核心優化思想都是減少回表次數進行優化處理。 標簽記錄法(錨點記錄法)我們再來看下一種優化思路,上述深度分頁慢原因我們也清楚了,一次性查詢的數據太多也是問題,所以我們從這個點出發去優化,每次查詢少量的數據。那么我們可以采用下面那種錨點記錄的方式。類似船開到一個地方短暫停泊之后繼續行駛,那么那個停泊的地方就是拋錨的地方,老貓喜歡用錨點標記來做比方,當然看到網上有其他的小伙伴稱這種方式為標簽記錄法。其實意思也都差不多。 這種方式就是標記一下上次查詢到哪一條了,下次再來查的時候,從該條開始往下掃描。我們直接看一下SQL: select * from Product p where p.timeCreated > "2020-09-12 13:34:20" and id>10000000 limit 10 顯然,這種方式非常快,耗時如下: 但是這種方式顯然是有缺陷的,大家想想如果我們的id不是連續的,或者說不是自增形式的,那么我們得到的數據就一定是不準確的。與此同時咱們也不能跳頁查看,只能前后翻頁。 當然存在相同的缺陷,我們還可以換一種寫法。 select * from Product p where p.timeCreated > "2020-09-12 13:34:20" and id between 10000000 and 10000010 這種方式也是一樣存在上述缺陷,另外的話更要注意的是between ...and語法是兩頭都是閉區域間。上述語句如果ID連續不斷地情況下,咱們最終得到的其實是11條數據,并不是10條數據,所以這個地方還是需要注意的。 存入到es中上述羅列的幾種分頁優化的方法其實已經夠用了,那么如果數據量再大點的話咋整,那么我們可能就要選擇其他中間件進行查詢了,當然我們可以選擇es。那么es真的就是萬能藥嗎?顯然不是。ES中同樣存在深度分頁的問題,那么針對es的深度分頁,那么又是另外一個故事了,這里咱們就不展開了。 寫到最后那么半夜三更爬起來優化慢查詢的小貓究竟有沒有解決問題呢?電腦前,小貓長吁了一口氣,解決了! select * from InventorySku isk inner join (select id from InventorySku where inventoryId = 6058 limit 109500,500 ) as d on isk.id = d.id 顯然小貓采用了inner join的優化方法解決了當前的問題。 相信小伙伴們后面遇到這類問題也能搞定了。 轉自https://www.cnblogs.com/kdaddy/p/18270217 作者程序員老貓 該文章在 2024/9/9 9:37:58 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886